
Table of Contents


The share of tech spending allocated to artificial intelligence is rising and will soar exponentially.
Organizations that integrate AI driven assistants into their workflows for greater efficiency, should consider integrating security measures within their systems.
The cost of data breaches isn’t restricted to losing consumer trust but extends to long, costly battles against governance agencies.
This challenge is currently addressed with effective data masking techniques. IBM’s research also suggests that organizations using AI security and automation are successful in containing data breaches 108 days earlier compared to organizations that do not use such systems.
What is Data Masking in Cybersecurity?
Data masking is an effective cybersecurity technique that transforms sensitive data while retaining the structure and behavior of the original data. In redaction, specific parts of data, such as personal details or financial information, are hidden or replaced (e.g., with Xs or asterisks) to protect privacy while leaving the rest of the data intact.
This enables organizations to test their systems without exposing sensitive data and improves the quality of their products while keeping their users’ privacy intact.
Regulatory bodies such as GDPR and CCPA hold organizations responsible for misuse of data. To ensure compliance and not incur reputational damages, organizations are protecting their confidential data and personally identifiable information of users’ (PII)
Data Masking can be used in multiple scenarios, including software development and testing, analytics, data warehousing and more. It’s ideal for large-scale data projects, such as cloud migrations and third-party app integrations, where there is a risk of exposing real information. It can also be used to create training datasets, which employees can access without exposing real-world data that could put them at risk of cyberattacks.
What Type of Data Requires Masking?

Data masking is usually required for sensitive data, including:
- Personally identifiable information such as names, passport/ID information and others.
- Payment information, such as payment card information and other types of information, must be protected by PCI-DSS and the US Federal Trade Commission.
- Protected health information includes health status and payment.
- Intellectual property data - includes the organization’s inventions, designs, and other high-value IP data.
Why Redaction is the Most Effective Form of Data Masking?
Context-aware redaction is a more nuanced approach than simply blacking out sensitive information. It selectively redacts data based on the context in which it appears, allowing for a more balanced approach between data protection and data utility.
Here’s how context-aware redaction can be advantageous compared to using fictitious or synthetic data:
1. Preserves Data Utility: By selectively redacting only the most sensitive parts of the data, context-aware redaction allows for more meaningful analysis and insights compared to completely masking or replacing the data.
Data relationships: It maintains the relationships between different data points, which can be crucial for understanding patterns and trends. Synthetic data, while statistically similar, may not fully replicate these intricate relationships.
2. Reduces Bias and Distortion: Realistic data: Context-aware redaction retains the original data, albeit with sensitive parts removed. This ensures the data remains realistic and representative of real-world scenarios. Synthetic data, while designed to mimic real data, can sometimes introduce biases or distort the original data distribution.
Accurate analysis: Preserving the original data, even with redactions, can lead to more accurate analysis and modeling compared to using synthetic data, which might introduce artificial patterns.
Examples of Context-Aware Redaction: Medical records: Redacting patient names and addresses while retaining diagnostic information and treatment history for research purposes.
Financial transactions: Masking specific transaction details like account numbers while preserving transaction amounts and dates for fraud detection analysis.
Legal documents: Redacting names of individuals involved in a case while retaining the factual information and legal arguments for public access.
Smart Contextual Redaction with Wald
Context-aware redaction offers a more flexible and intelligent approach to data masking. It allows you to protect sensitive information while preserving the valuable insights and utility of the original data, often surpassing the capabilities of fictitious or synthetic data.

Data Masking vs. Obfuscation
Data masking falls under the umbrella term known as data obfuscation, which conceals sensitive data and makes it useless in the hands of an attacker. Data masking is also known as data shuffling, data scrambling or blinding and is the most popular type of data obfuscation method. The other common data obfuscation methods are encryption, tokenization and randomization.
Data masking and obfuscation are distinct techniques for protecting sensitive information, but they differ in critical ways.
- Usability of output: Data masking alters data in a way that retains its utility for testing and development purposes. For example, a masked credit card number might still adhere to the format and validation rules of a real card, enabling realistic testing scenarios. Obfuscation methods, such as encryption or tokenization, render data unusable for such purposes. The encrypted or tokenized output serves primarily to protect the data, not facilitate its use.
- Reversibility: Data masking is typically a one-way process, but with a decryption key it can retrieve the initial data, this gives complete control and flexibility to an organization. Wald also enhances security by ensuring that even if this masked data is compromised, the original sensitive information remains protected. In contrast, reversibility in obfuscation depends on the type of the process; the hashing technique under obfuscation is irreversible, while tokenization is only reversible with the relevant lookup table and the encryption technique is completely reversible.
In addition to these differences, it’s important to consider the level of granularity each technique offers. Data masking often allows for fine-grained control over how data is altered, enabling customization based on specific needs. Obfuscation methods tend to be more coarse-grained, applying a uniform transformation to the entire data set.
Data Masking vs. Data Anonymisation
Both of these are techniques to protect sensitive data. One of the key differences is in the reversibility of data i.e. being able to track or link the data back to the user.
Data Anonymisation = Absolute privacy, irreversible process
Data Masking = Privacy + flexibility, reversible process
Depending on an organization’s use case, it’s essential to choose the right kind of data protection technique. Wald understands the need for privacy, flexibility and compliance. We combine data masking techniques to ensure the safety of your data and provide you with accurate results while using it.
Data Masking vs. Data Obfuscation vs. Data Anonymization - Examples
Data Masking
Training the GenAI model to detect credit card fraud involves using credit card numbers in the training set among realistic parameters. Mask the credit card number, for example - 1234-5678-9012-3456, by using Xs for all the numbers except the last four (e.g., XXXX-XXXX-XXXX-1234). This shields sensitive data from being exposed but allows the model to recognize trends.
Data Obfuscation
For instance, consider the process of developing a GenAI model using customer assistance transcripts. You do not use the real and full names of the customers and instead use a name such as “Customer123” or “Jane Doe”. The data pattern exists, but the substantiated identifying data is concealed.
Data Anonymization
A health center wishes to leverage the power of GenAI in data derived from patients. They first anonymize the dataset by cleaning all primary identifiers (such as name, address, and social security number) and perform other processes, including generalization (for example, changing combinations of ages to age groups) and data perturbation (adding random noise to data). This ensures that the re-identification of individuals is almost impossible while still keeping the needed data for analysis.
Types of Data Masking
There are several different types of data masking, including static, dynamic, and “on the fly” data masking.
Static Data Masking
Static data masking is essentially a duplicated version of a dataset that can be either fully or partially masked. This dataset is usually maintained separately from the production database. It includes applying a fixed set of masking rules to sensitive data before it is shared or stored.
Dynamic Data Masking
Dynamic data masking is the masking of data in real-time. Dynamic masking is applied directly to the production dataset and is done at a time when the users access the data. This dynamic data masking type comes in handy for preventing unauthorized data access.
On the Fly Data Masking
As the name suggests, on-the-fly data masking masks data on the go. For instance, when sensitive data is transferred between environments, it is masked before reaching the target environment.
This essential data masking type allows organizations to successfully mask data while it is transferred between environments.
Key challenges in Data Masking :
- Data Usability: Ensuring masked data remains useful for testing, development, and analysis while protecting sensitive information
- Performance Impact: Large datasets can slow down systems due to resource-intensive masking processes
- Format Preservation: Maintaining original data format and uniqueness while keeping data recognizable
Due to these challenges, many organizations turn to Wald to efficiently mask data while preserving its value and integrity.
Top 3 Powerful Data Masking Techniques Used by Wald
Wald employs a variety of data obfuscation techniques to ensure sensitive information is protected while maintaining its usability for analysis and development. Below, we will explore the types of redactions and substitutions used for data obfuscation, our context-aware rephrasing is a smart identifier of the kind of sensitive data that needs redaction and deciding up to what degree it needs to be redacted to keep it functional yet secure.
1. Data Redaction - Definition: Redaction is a technique of concealing particular data points inside a data source such that they remain operational but out of the reach of unauthorised individuals.
Context Intelligent Rephrasing: Rather than revealing PII data of clients and confidential sales data, we identify such sensitive data and appropriately mask it.

2. Substitution and Smart Rephrasing - Definition: This technique replaces sensitive data with fictitious but realistic values.
*Context Intelligent Rephrasing:* Wald substitutes the original data with realistic placeholders that allow for continued analysis without the threat of exposing actual data.
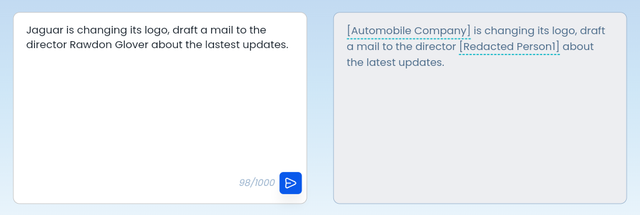
3. Encryption - Definition: Data encryption transforms sensitive data into encrypted code. Wald secures conversations using a key which the user brings. Only admins of the account have access to see the original input
Context Intelligent Rephrasing: Protecting sensitive information from unauthorized access but releasing it when required in a secure environment.
Wald uses a variety of techniques to keep sensitive information safe while still allowing organizations to use their data for analysis and development. By applying methods like data masking, substitution, encryption, and anonymization, Wald helps businesses stay compliant with privacy rules and protect against unauthorized access. These strategies not only boost security but also ensure that data remains useful for important business tasks.
FAQs
Q. What are the common data masking techniques?
A. Summary of Common Data Masking Techniques
Q. What is context aware redaction?
A. Context aware data redaction is a technique that identifies and understand the type of sensitive data that needs protection but also retains its essence.
Q. Why should I use redaction?
A. To prevent the exposure of any sensitive client data and company proprietary data and to secure employee conversations with generative AI assistants such as ChatGpt, Claude, Gemini and more.



